
SCEPTR#
SCEPTR (Simple Contrastive Embedding of the Primary sequence of T cell Receptors) is a small, fast, and accurate TCR representation model that can be used for alignment-free TCR analysis, including for TCR-pMHC interaction prediction and TCR clustering (metaclonotype discovery). Our preprint demonstrates that SCEPTR can be used for few-shot TCR specificity prediction with improved accuracy over previous methods.
SCEPTR is a BERT-like transformer-based neural network implemented in Pytorch. With the default model providing best-in-class performance with only 153,108 parameters (typical protein language models have tens or hundreds of millions), SCEPTR runs fast- even on a CPU! And if your computer does have a CUDA-enabled GPU, the sceptr package will automatically detect and use it, giving you blazingly fast performance without the hassle.
sceptr’s API exposes three intuitive functions: calc_vector_representations(), calc_cdist_matrix(), and calc_pdist_vector()– and it’s all you need to make full use of the SCEPTR models.
What’s even better is that they are fully compliant with pyrepseq’s tcr_metric API, so sceptr will fit snugly into the rest of your repertoire analysis toolkit.
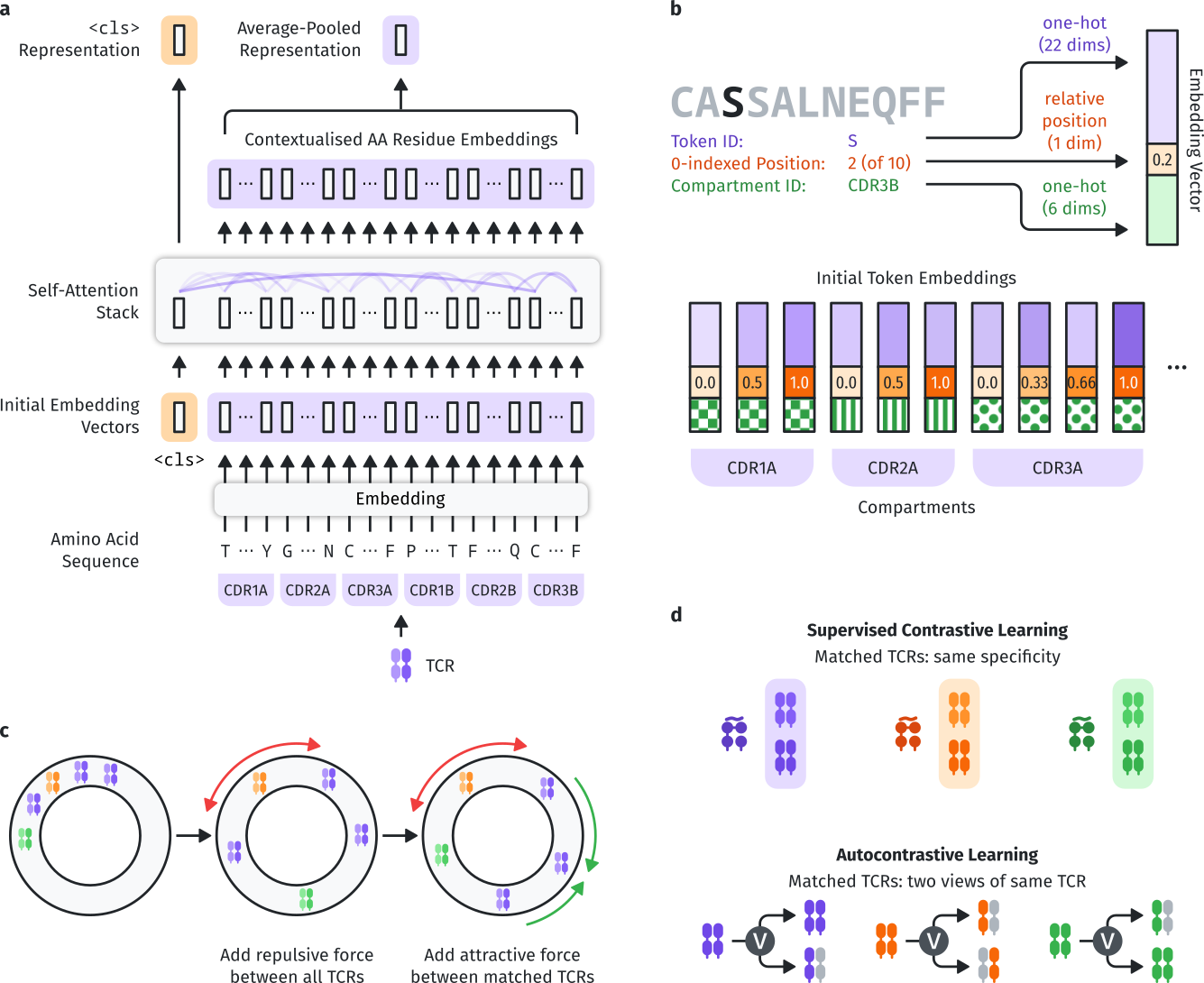
A visual introduction to how SCEPTR works, taken from our SCEPTR preprint.
SCEPTR is a TCR language model (a,b) pre-trained using masked-language modelling and autocontrastive learning (c,d).
(a) The default model uses the <cls> pooling method, but there is also a variant that is trained to use average-pooling (see sceptr.variant.average_pooling()).
Please see the preprint for more details.#